
À l’heure où Google Books affirme avoir scanné plus de 40 millions de titres en 15 ans d’existence, la dématérialisation du livre est un fait acquis. Rares sont ceux qui n’y ont jamais eu recours, de même qu’à la reconnaissance optique de caractère (OCR – Optical Character Recognition) qui permet d’extraire le texte d’un facsimilé numérique qui en contiendrait. Si cette technologie désormais grand public donne des résultats satisfaisants sur des textes imprimés, le défi reste de taille en ce qui concerne la transcription automatique de manuscrits – on parle dans ce cas de HTR (Handwriting Text Recognition). Pouvoir accéder aux sources manuscrites sans passer par la case transcription : bien des chercheur·euses en rêvent secrètement – et sans oser l’avouer. Le projet de numérisation et de publication des procédures criminelles de la principauté de l’ancien Évêché de Bâle cherche justement à développer des outils qui permettront de faciliter l’accès aux documents originaux, parmi lesquels des modèles HTR.
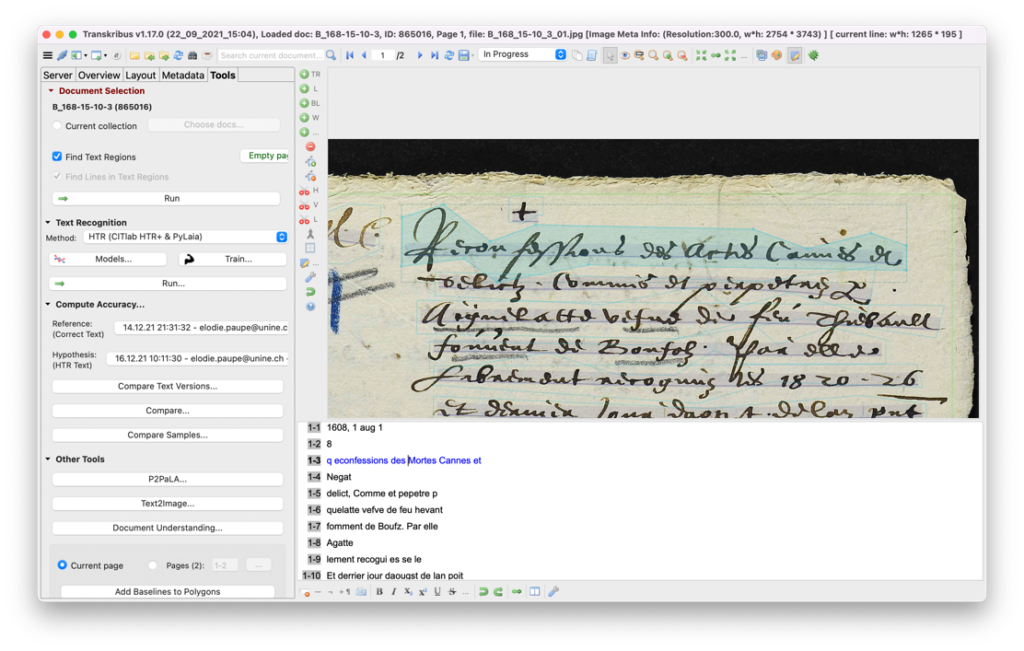
Dans le cadran supérieur, segmentation en lignes ; dans le cadran inférieur, transcription réalisée à partir d’un premier modèle. Capture d’écran du logiciel Transkribus.
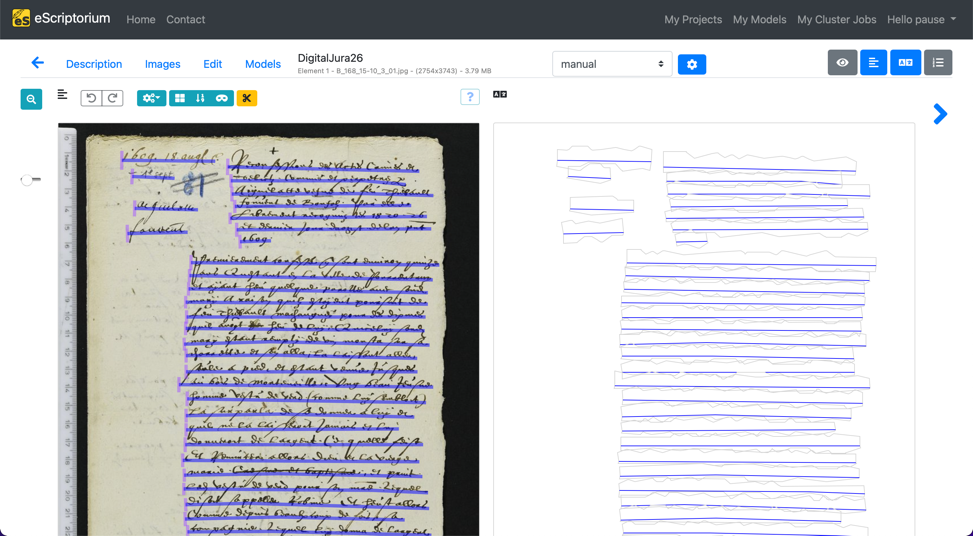
Dans le cadran gauche, segmentation en lignes ; dans le cadran droit, zone de transcription vierge. Capture d’écran de l’interface eScriptorium du projet FoNDUE.
Ce projet qui débute en 2022 a servi de support à une journée d’étude intitulée Digital Jura. Organisée par l’Université de Neuchâtel en partenariat avec les Archives de l’ancien Évêché de Bâle (AAEB), elle s’est tenue le 17 décembre 2021 à Porrentruy. L’objectif de cette journée coorganisée par Simon Gabay de l’Université de Genève et Élodie Paupe de l’Université de Neuchâtel était de faire découvrir les enjeux liés à la reconnaissance automatique des écritures manuscrites et s’articulait en deux temps : le matin était consacré à la question de la segmentation et l’après-midi au HTR. Il s’agissait notamment de présenter deux outils capables de reconnaître des zones sur une page (notes, titre courant, numérotation, illustration…), puis de reconnaître, le cas échéant, le texte dans ces zones. Un des outils est bien connu des chercheur·euses, Transkribus, l’autre est une infrastructure en cours de développement à l’Université de Genève, FoNDUE.
Les différentes étapes du développement d’un modèle HTR ont ainsi été présentées et un premier modèle entraîné sur un corpus de 5’502 mots grâce à Transkribus. Le volume de cette vérité de terrain correspond à la fourchette basse du volume de données recommandées pour le développement d’un modèle (entre 5’000 et 15’000 mots). Ce modèle (AAEBv1) est donc un premier jalon qui permettra d’évaluer le ratio entre l’apport de nouvelles données d’entraînement et l’augmentation de la précision. Le taux d’erreurs dans la reconnaissance de caractère de 14,6 % est ainsi amené à diminuer.
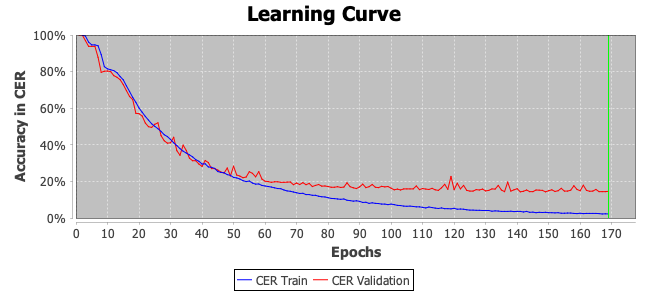
La ligne d’apprentissage présente l’évolution à chaque epoch. Après 169 tours d’apprentissage, le taux d’erreur sur les données d’entraînement s’élève à 2,2 % et il monte à 14,6 % pour les données de validation.
En fait, la quantité de données nécessaires à l’élaboration de modèles va dépendre de plusieurs facteurs, notamment de la difficulté de lecture de la main. Il est toutefois possible de réduire ce volume en s’appuyant sur les performances d’un modèle antérieur. Dans le cas qui nous occupe, la situation est rendue plus compliquée du fait des multiples individus qui ont rédigé les procédures criminelles dans les divers bailliages de l’ancien Évêché de Bâle du XVIe au XVIIIe siècle. Deux démarches étaient possibles pour faire démarrer le projet : soit viser le développement d’un modèle général, soit tenter le développement d’un modèle pour une main fréquente dans ce corpus. Pour différentes raisons, c’est la seconde option qui a été choisie. En effet, un scripteur s’est détaché du lot pour des raisons quantitatives, mais également qualitatives, le prévôt Henri Farine, actif de la fin du XVIe siècle à sa destitution en 1618. D’une part en effet, son écriture est assez régulière et relativement lisible et, d’autre part, il est le rédacteur d’environ un cinquième des pièces figurant dans les procès de sorcellerie durant sa période d’activité.
Le projet s’oriente donc vers le développement d’un modèle HTR performant fondé sur la main de ce scripteur, par ailleurs également bien représenté dans d’autres sources conservées aux AAEB, pour un total qu’on peut évaluer à au moins 3’500 pages. Nous espérons que ce modèle puisse servir de base au développement d’un modèle générique pour les mains des textes français du XVIIe siècle.
Suggested citation: Paupe Elodie, Lire un manuscrit à l’aide du numérique: Développement d’un modèle HTR, Blog of the LexTech Institute, 8 February 2022
Author(s) of this blog post

PhD Student in latin philology, Elodie Paupe is interested on digital philology, digitalization of sources and automatic transcription.