
Federated learning (FL) is an increasingly popular decentralized machine learning (ML) paradigm. FL client devices share with a trusted server only their local individual updates of a given ML model held in memory by all clients, rather than the data used to train it. These updates are called gradients, and are produced when clients run the ML model on their data locally. Notable examples of updates include the images captured by an autonomous car’s camera, or when building a specific voice model for Amazon Alexa. This FL approach protects by design the privacy of user data, usually of highly sensitive nature.
The trusted FL server is known by all nodes and its role is to build a global model, usually aggregating all the gradients. Once the server has aggregated the gradients from all clients, it broadcasts back an updated version of the model to all clients, and all nodes can continue to train (i.e., improve) the model.
To work correctly, FL model updates always correspond to one specific version of the model. Hence, by design, all clients always share the same copy of the ML model. This decentralized training comes with a shared weakness: if a malicious client (i.e., an attacker) crafts fake data (e.g., an ambiguous picture) that deceives its copy of the model, then this data would deceive the other clients’ models too if presented to them. Such an ambiguous data sample is called an adversarial example. It is easy to craft when all the parts of the model are known to the attacker, which is the normal case, by reading its own device’s memory. Such fake data crafting process is called an adversarial attack.
Deceiving could mean that the model doesn’t classify an object correctly: for example, patch attacks famously create a sticker that, once put on a clear road sign, transforms it into an adversarial example, wrongfully perceived as a hill by an autonomous car to potentially cause an accident. A similar scenario happens when camouflage tricks the human eye, inducing a form of misclassification (e.g., someone hidden in a bush wearing a camouflage vest is misclassified as part of said bush). Deceiving might suggest that the attacker found some gibberish that is classified as a correct input. In this case, the model updates are corrupt gradients sent to the server that stem from bogus data (an adversarial sentence captured by Amazon Alexa) instead of a normal life speech sample, thus undermining the average quality of the aggregated updates. The figure below illustrates the aforementioned interactions between a server and collaborating clients and the producing of an adversarial sticker over a clean road-sign.
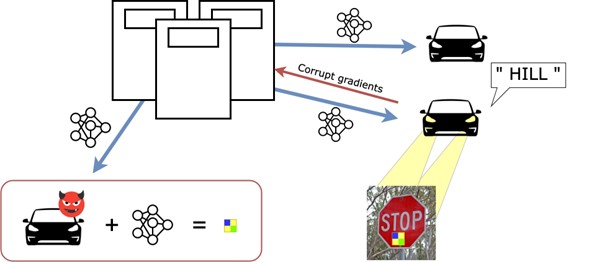
Existing solutions fail to mitigate the crafting of these adversarial samples because it is generally considered infeasible to prevent an attacker to access the entirety of the model.
Instead, we propose a system doing exactly that: limiting what is physically available to the attacker. Intuitively, if we prevent a malicious client from accessing parts of the model from its own local device memory, then it cannot efficiently craft those adversarial examples. This is nowadays a realistic assumption: several ARM processors found in commodity devices deployed in FL schemes use TrustZone -a combination of hardware and software technology- to control special parts of the processor, i.e., memory enclaves, to isolate parts of its own device’s memory from the client. Data stored in enclaves at the request of the server cannot be accessed by the client anymore. Especially in mobile devices, enclaves are strongly limited (around 30 MB): consequently, hiding the entirety of modern ML models (10+ of GBs) is not practical. So, one has to decide which specific portions (the most important, revealing ones) should be stored in those client-side enclaves, preventing the launch of those adversarial attacks.
In our benchmarks using real-world datasets and models, it is sufficient to isolate a small percentage of model (<0.01%) to successfully mitigate such attacks. In some scenarios, we achieve a full mitigation. In the road signs scenario, it means that the crafted adversarial patches do not lead to a misclassification (see figure above for a no-defense/defense comparison).
Our mitigation approach preserves the robust accuracy (the ability to tell apart fake from true data) of the victim models despite the attempts at deceiving them. Additionally, our method scales well when larger models are used: we applied it to small ResNets as well as large Vision Transformers (ViT-L/16), while being restricted by the underlying hardware limitations.
Preliminary results of this work have been presented at the 3rd Workshop on Distributed Machine Learning (DistributedML’22).
Proposition de citation: Schiavoni Valerio/Queyrut Simon, Using enclaves against adversarial attacks in federated learning – How to drive safely your Tesla against road-warriors?, Blog of the LexTech Institute, 07.02.2023